

The headline
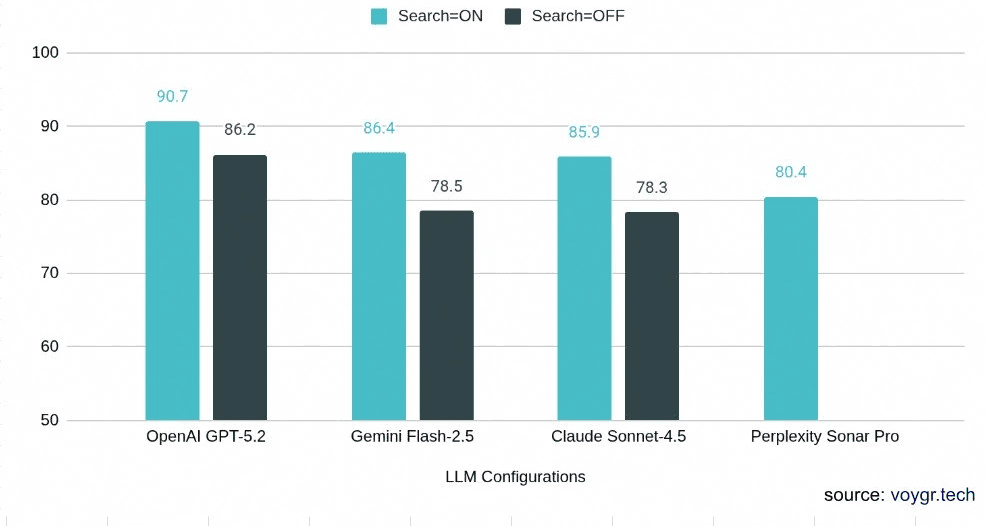
OpenAI leads (90.7/100), followed by Gemini (86.4), Claude (85.9), and Perplexity (80.4). But no single provider wins everything — rankings shift by task type, and even the best model fails badly 8% of the time.
Without search, 1 in 5 places Claude recommends doesn't exist, is permanently closed, or is in the wrong location. Even with search, no provider reliably detects closed venues — all 7 configs confidently gave booking guidance to a shuttered Buenos Aires restaurant.
The surprise
Web search helps on factual lookups (+8 points) but hurts on transactional tasks — Claude and Gemini both lose 5+ points on booking prompts when search is enabled. Search returns facts about a place instead of guidance on how to act.
Constraint fidelity — whether the recommendations actually match what you asked for — varies 16 points across providers. All models find real places; not all find the right places.